

My Blog Syndication Strategy 📣
My blog syndication strategy keeps souravdey.space as the canonical source, with Dev.to and Hashnode as discovery layers instead of separate homes.

Hi folks! I am a 👨💻 Full-Stack Developer, occasional Designer, and Blogger facilitating the world with User Experience 🧐 as a Design Thinker 💭 and User-Centric Developer 💯 and while also exploring ☁️ Cloud
Working 💼 @HackerRank as a Software Development Engineer 2
🤓 I have a keen interest in 🤝 collaborating with others and empowering others to build digital solutions that solve real-world 🌍 problems. I'm a Creative Technologist who believes that the merger between Design Thinking and Digital Technologies will lead to the building of user-centric solutions that are impactful toward the betterment of business & society.
For a long time, I treated publishing a blog post like crossing a finish line. I would write the post, hit publish, share it once, and move on. It felt tidy. It also meant I kept confusing publication with discovery. 😅
My blog syndication strategy came from that mistake. 📌
The source of truth lives on souravdey.space. Dev.to and Hashnode help me distribute the same idea further, but they do not become the home of the work. That distinction sounds small until you have been writing long enough to care about URLs, long tails, and the difference between being discoverable and being dependent.
I wrote about this in Portfolio Website Development Part 4, where I said I should have moved canonical hosting to my own domain much sooner. I meant that. The older I get in public writing, the less romantic I am about platforms. A platform is useful. A platform is not ownership.
The workflow at a glance
This is the shape I keep in my head.
Flow: Write the blog, open a PR, merge it into main, then let GitHub Actions fan the post out to Dev.to, Hashnode, Medium, and the GitHub issue checklist.
The process is simple: I write the blog, I open a PR, and once that PR lands in main, GitHub Actions pick up the follow-up work.
At the command line, the ritual is small enough to remember:
yarn build
yarn crosspost -- blog-syndication-strategy
The first command checks whether the post can survive syndication cleanly. The second is the escape hatch I use when I want to inspect or trigger a single post by hand.
What those two commands actually do
This looks tiny. It is not tiny.
yarn build is my rehearsal. In this repo it does not just build the Next.js site. It runs yarn check:syndication first, then the site build. So before I ever merge, the pipeline has already asked a useful question: if this post leaves my website, will it still make sense?
yarn crosspost -- slug is narrower and more practical. It resolves one MDX file, reads the frontmatter, converts the body into platform-friendly Markdown, talks to the Dev.to and Hashnode APIs, and updates the saved crosspost state so the next run knows whether it is creating something new or updating something that already exists.
That division matters. One command protects quality. The other handles distribution.
The mental model in code is even simpler: publish once, then automate the platform copies that are truly repeatable.
const syndicationTargets = ["Dev.to", "Hashnode"] as const;
function publish(post) {
publishCanonical(post);
syndicationTargets.forEach((target) => {
crosspost(post, target);
});
}
publishCanonical(post) is the whole philosophy in one line. Home first. 🏠
Then the loop fans out only across targets that are predictable enough to automate. That is why the array is short. Dev.to and Hashnode fit that model. Medium does not sit in that loop because the action I care about there is different. I do not want “post some Markdown.” I want “import this canonical URL and preserve the original source.”
Medium stays outside that automated loop on purpose. I handle it manually through link import, because preserving the canonical URL matters more to me than forcing every destination to behave the same way.
There are GitHub Actions around this too. I think of them as guardrails, not magic. The local commands are how I work. The workflows are how I stop that process from depending on my memory.
Canonical first
My site is where the post starts, where it gets updated, and where it stays.
That choice shapes everything else. I write in MDX under src/content/blogs, and the frontmatter decides whether a draft is ready to leave the building. If a post is published, the site treats it as part of the content graph, not as a one-off asset. Search, sitemap entries, RSS, structured data, and the page itself all point back to the same canonical home.
That is the part I care about most.
If someone finds me on Dev.to or Hashnode, I still want the post to know where home is. If search finds the original article, I want that version to be the one search engines remember. If I update the post later, the canonical copy should be the one that carries the truth forward.
Ownership is not just a philosophical preference. It is a maintenance strategy.
What the actual loop looks like
The loop is simpler than it sounds.
I write the post. I open a PR. Review happens there. When that PR lands in main, that is the moment the canonical post becomes live and the follow-up automation starts.
Before any of that merge machinery matters, yarn build runs the syndication checks locally so I get early feedback if a post contains something the crosspost pipeline cannot translate cleanly.
Then GitHub Actions repeat that discipline in CI.
What the GitHub Actions actually do
The first workflow is syndication-check.yml. It runs on pull requests and on pushes to main when blog files or the syndication code changes. I like that detail more than I expected to. It means the check is not some vague “content pipeline” that wakes up for everything. It wakes up only when the parts that matter change. If I change the syndication logic, or I change a blog post that will be published, the workflow reruns the exact question I care about: can this MDX survive outside my site without falling apart?
That workflow is the skeptical friend in the system. 👀 It does not publish anything. It just refuses to let me feel prematurely done.
At the YAML level, it is doing something very plain:
on:
pull_request:
paths:
- "src/content/blogs/**"
push:
branches: [main]
That is not glamorous. It is also the reason the workflow feels trustworthy. It runs when blog content changes, and when the code that handles syndication changes. Not on every random edit in the repo.
The second workflow is post-publish-blogs.yml, and this one is the real follow-through. It runs only after content lands on main. That boundary matters to me. Drafting is one phase. Review is another. Distribution starts only when the canonical post is actually live on my domain.
Once that workflow wakes up, it diffs what changed, filters down to published blog slugs, and runs the follow-up work in one place. It can generate OG thumbnails when the image is missing, create audio, crosspost to Dev.to and Hashnode, send social announcements, and open the GitHub distribution checklist issue that reminds me about the manual side of the job. Medium lives there indirectly. Not as an automated API call, but as a deliberate item in the checklist.
The code path is surprisingly readable:
const publishedSlugs = publishedBlogSlugsFromChanged(changed);
runOgThumbnails(publishedSlugs);
runAudio();
crosspostOk = runCrosspost(publishedSlugs);
socialOk = runSocialAnnounce(publishedSlugs);
runDistributionChecklist(publishedSlugs, crosspostOk, socialOk);
That sequence is the process in miniature. First figure out which published posts actually changed. Then do the repeatable work around them. Then open the checklist for the parts that still deserve a human hand.
That is the real payoff for me. I do not want to remember five slightly different publishing rituals. I want one publishing model. Let the machine handle repetition. Let me handle judgment.
The crosspost layer does the boring work well. Under the hood, it is basically this:
const markdown = mdxToCrosspostMarkdown(body, siteUrl);
const footer = originAttributionFooter("souravdey.space", siteUrl);
What that conversion code is really doing
That little pair of lines carries most of the weight. It turns MDX into platform-friendly Markdown, absolutizes links, strips out components that only make sense on my site, and adds the attribution footer that tells readers where the original lives. In practice, that is the bridge between the thing I enjoy writing and the thing platforms are willing to accept.
mdxToCrosspostMarkdown is the messy realism function in this whole setup. It is where custom site-only components stop being UI elements and start becoming readable plain Markdown. It is where local image paths become absolute URLs. It is where embeds that work beautifully on my site turn into links, summaries, or simplified fallbacks for platforms that do not know anything about my component system.
originAttributionFooter is simpler, but maybe more important. It is the line that keeps ownership visible after the post travels. Without that footer, syndication can quietly become duplication. With it, the copied post still remembers where home is.
There is another small detail here that makes the whole setup feel grown-up to me. The post-publish workflow commits generated assets back with [skip ci], so the automation does not keep waking itself up in a loop. That sounds like a tiny implementation detail. It is also the difference between “automation” and “a bot that eats its own tail.” ♻️
A blog post is not done when I finish writing it. It is done when it survives distribution without losing its shape.
That is a different bar.
The GitHub issue checklist
The automated path is only half the story. I also keep a GitHub issue open for the manual side of distribution, so Medium, social shares, and aggregator submissions do not live in my head. The issue is created from the post metadata and labeled distribution by the same follow-up workflow that handles crossposting.
That part matters more than it sounds. A lot of publishing systems look “automated” right up until the moment they quietly dump the human steps back into your brain. I did not want that. If a step is manual, I still want it in the system. Visible. Attached to the post, not floating around as a half-remembered note.
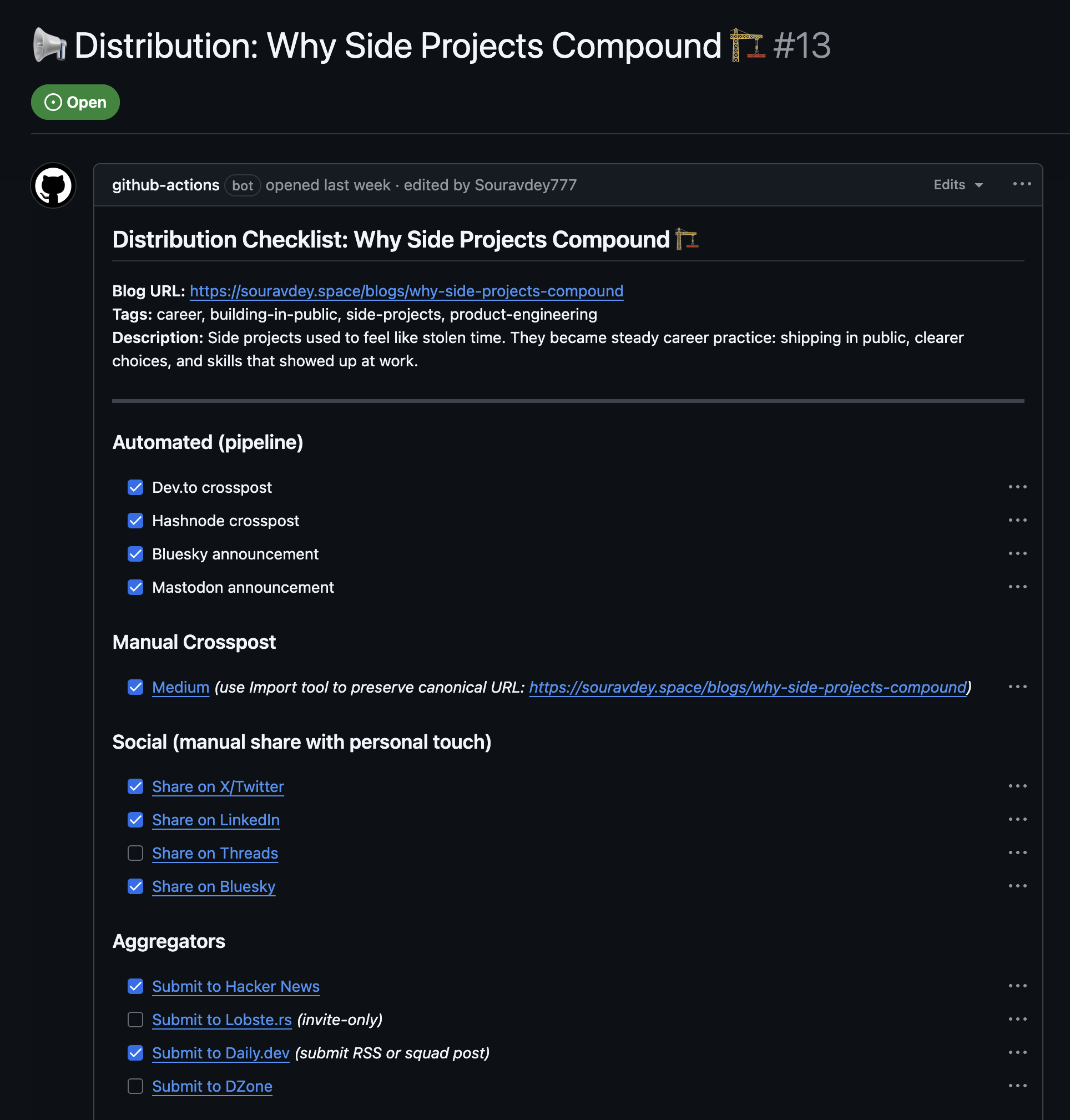
The Medium row is still a direct link paste, because I want the import tool to preserve the canonical URL:
- [ ] [Medium](https://medium.com/new-story) *(use Import tool to preserve canonical URL: https://souravdey.space/blogs/blog-syndication-strategy)*
That line is intentionally verbose. I do not want future me guessing what “publish to Medium” meant on a sleepy evening.
And if I need to recreate the issue itself by hand, the CLI version is straightforward:
gh issue create --title "📢 Distribution: My Blog Syndication Strategy 📣" --label distribution --body-file checklist.md
That checklist is the human half of the system. It catches the little things automation should not guess.
Why I still syndicate
I do not syndicate because I am unsure where my work belongs.
I syndicate because attention is fragmented, and readers do not all arrive through the same door. Some people discover a post through Dev.to. Some through Hashnode. Some through RSS. Some through search. Some land on my homepage because they already know my name. I want to meet all of them without making every post depend on one channel.
That is the balance I was after: reach without surrendering the original. ✨
If I only published on my own site, I would own everything and reach fewer people. If I only published on platforms, I would get reach and lose some control. Syndication is the middle path I actually believe in. It is not a compromise if the canonical story is strong.
There is also a softer reason. Crossposting makes my writing travel. A good post should be able to sit in different places and still feel like the same thought. That constraint makes me write cleaner, structure better, and keep my MDX honest. If a post depends too heavily on site-specific presentation, I usually need to think harder about whether the core idea stands clearly enough on its own.
The tradeoffs are real
I am not pretending this setup is free.
Every layer of automation adds another place where content can break. Some MDX components do not translate neatly. Some images need better alt text than I would otherwise bother with when I am in a hurry. Some internal links need to become absolute URLs on syndicated copies. That is why I like having check:syndication wired into the build. I would rather learn about a conversion problem before the post is public than after I have shared two broken copies.
There is also a mental tradeoff. Syndication can tempt you into caring too much about platform performance. I try not to let that happen. If Dev.to gets more clicks on one post and Hashnode gets more comments on another, that is interesting, but it is not the point. The point is that the original post stays intact, searchable, and under my control.
I want the platform to amplify the writing, not define it.
That line keeps me honest.
What I would do differently
I would move canonical hosting to my own domain even earlier.
That is the cleanest lesson in the whole thing. For years I cared too much about where a post could travel and not enough about where it should live. In Part 4 I admitted that. The older version of me thought syndication was a distribution decision. The better version of me sees it as an architecture decision.
I would also document my content conventions sooner. Once a site has more than one content type, memory stops being a reliable system. Frontmatter, tags, images, series, and syndication rules all start to interact. A short internal doc saves future me from guessing, and guessing gets expensive when it happens at publish time.
If I were starting again today, I would still syndicate. I would just be much less sentimental about the platform copy and much more protective of the original.
That is the whole strategy, really.
Write once. Keep the canonical copy at home. Let other platforms do the discovery work. Update the source, and let the copies follow.
The original should always know where home is. 🏠
Originally published at souravdey.space.


